Al’s Discount AI
OpenAI (pvt) has announced a substantial price cut for its flagship reasoning o3 model, and when we say substantial, the cut was 80% for both input and output tokens. This brings the model pricing down to a level similar to that of competitive models like Google’s Gemini 2.5 Pro, Anthropic’s (pvt) Opus 4, and DeepSeek’s (pvt) reasoning suite. At the same time it points out the arcane science of model pricing, a sometimes opaque system that can involve a number of different parameters. In the back of our mind however, every time we hear anything about model pricing a bell rings that asks “Will this be a major moneymaker for those that have spent millions or billions building infrastructure or training models?”, or will it become a ruthlessly competitive market where price competition will dominate and profits will be minimal?
We believe it is too early to answer the question but getting an understanding of how model pricing works and what drives pricing dynamics, at least at this point, is essential for having a basis for understanding how model pricing will play out over the next few years. Here are the most common model pricing types:
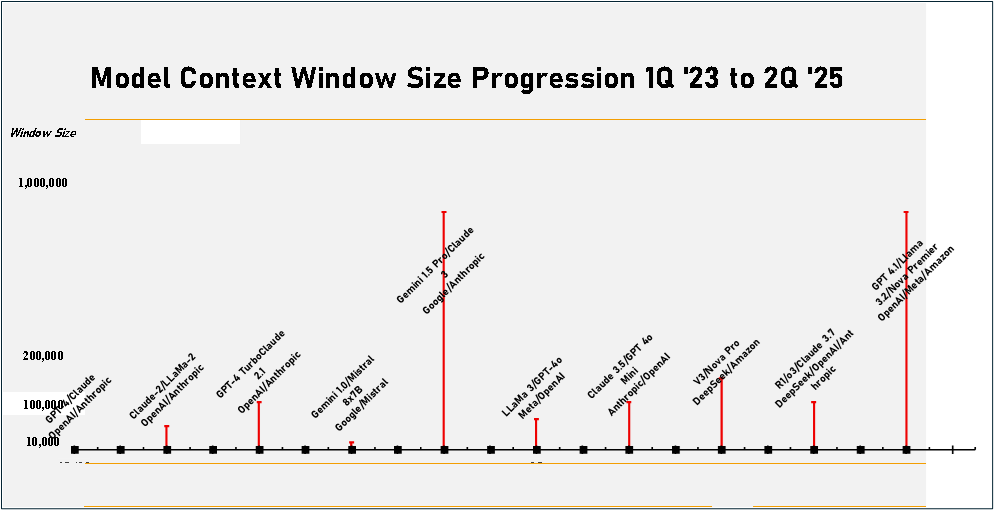
In the timeline below we show the progression of model context window size from 1Q 2023 to 2Q 2025. Early models had context windows that could handle less than 10,000 tokens or ~7,500 words. Over time that has progressed to 1,000,000 tokens or about 6 ½ average size books or 2,500 pages and has become a key model selling point as it reduces the need to break up large queries into smaller chunks that have to be processed individually. Large context windows do have a cost in terms of memory usage, computational overhead, and slower response time, and the model has less ability to focus on specific details, essentially wasting the model’s time sorting through a large token base, but large windows are ideal for searches in very long documents where the entire document can fit into the context window in a single pass.
We believe it is too early to answer the question but getting an understanding of how model pricing works and what drives pricing dynamics, at least at this point, is essential for having a basis for understanding how model pricing will play out over the next few years. Here are the most common model pricing types:
- Token-based - The most often used pricing model for AI systems is token based. Tokens represents the smallest unit of text that an AI model processes, which can be a word, a number, or even a punctuation mark. For reference, 1,000 tokens equals roughly 750 words. This pricing system is not only the most transparent for the user but ensures that the model is billing for actual usage, regardless of scale.
- Subscription based - Consumer-facing models tend to be subscription based, utilizing fixed rate pricing based on model access and type. There are access levels that can allow unlimited access or unlimited usage and give the user a predictable cost within access parameters.
- User-based – More common in enterprise and team oriented situations, users are each charged a flat fee on a monthly basis which simplifies billing and managing multiple users.
In the timeline below we show the progression of model context window size from 1Q 2023 to 2Q 2025. Early models had context windows that could handle less than 10,000 tokens or ~7,500 words. Over time that has progressed to 1,000,000 tokens or about 6 ½ average size books or 2,500 pages and has become a key model selling point as it reduces the need to break up large queries into smaller chunks that have to be processed individually. Large context windows do have a cost in terms of memory usage, computational overhead, and slower response time, and the model has less ability to focus on specific details, essentially wasting the model’s time sorting through a large token base, but large windows are ideal for searches in very long documents where the entire document can fit into the context window in a single pass.
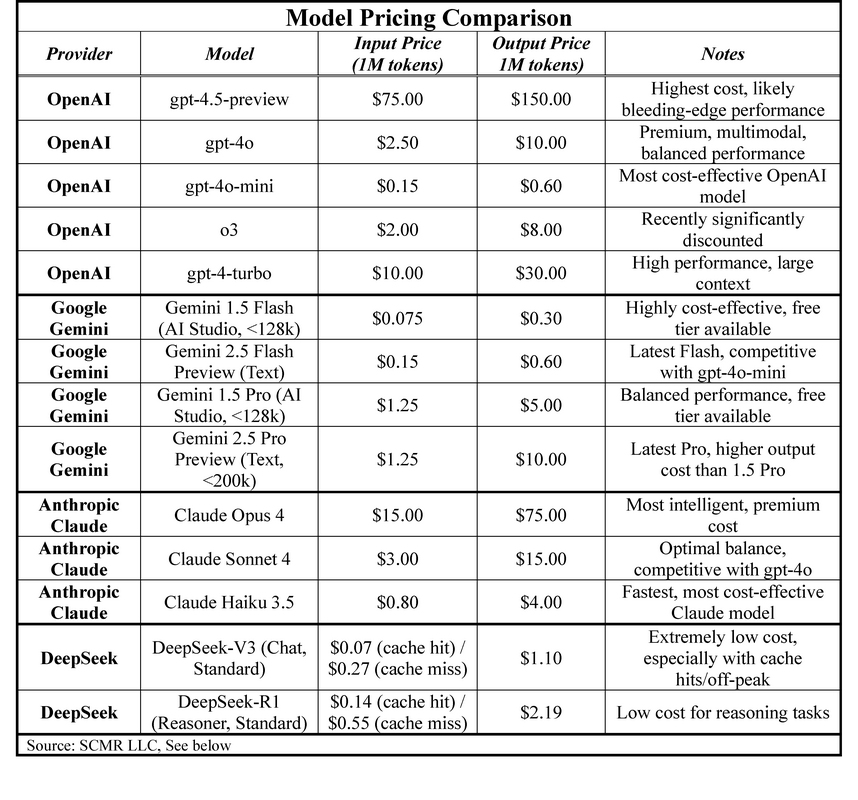
The model price comparison table shown below points out that that model pricing has already become a competitive market, but it remains a cost vs. performance evaluation for commercial users and enterprises. There are ways to offset some of the costs (volume discounts, off-peak processing, etc.) but model selection (performance needs) and cost make up most of the decision process, however as the number of large models continues to increase there are additional lower cost alternatives that continue to bifurcate pricing tiers.
The price comparison table shows that Google’s Gemini 2.5 Flash and DeepSeek’s V3 models are the most cost effective, while OpenAI’s GPT 4.5 (Preview) is the most costly. We expect model brands will begin to stake out price/performance tiers more specifically over the next year, but with performance increasing rapidly against a backdrop of increasing training costs, models that can provide lower cost training without sacrificing quality will have an edge. Deepseek is pursuing such a path but faces the fact that its servers are hosted in China and are therefore subject to Chinese PIPL and DSL rules, allowing the Chinese government access to said data under national security rules, ruling out US companies using these models for anything other than generic processing.
The price comparison table shows that Google’s Gemini 2.5 Flash and DeepSeek’s V3 models are the most cost effective, while OpenAI’s GPT 4.5 (Preview) is the most costly. We expect model brands will begin to stake out price/performance tiers more specifically over the next year, but with performance increasing rapidly against a backdrop of increasing training costs, models that can provide lower cost training without sacrificing quality will have an edge. Deepseek is pursuing such a path but faces the fact that its servers are hosted in China and are therefore subject to Chinese PIPL and DSL rules, allowing the Chinese government access to said data under national security rules, ruling out US companies using these models for anything other than generic processing.
While the AI model business is new and in a high growth stage, it has the same characteristics as any other high volume, user-based, feature oriented systems and is already being molded by the competition between model brands, even though most of these brands are still in a non-profit mode (not all). As the financial constraints of model training continue to expand, the need for profitability will become the primary driver and pricing will have to reflect that, but the need to drive user growth will make Ai pricing an even more competitive schema. We expect China will be the low-price leader but constrained by politics, while the big players like Google, Meta (FB), and OpenAI will battle it out on a feature-by-feature basis in a “We might be expensive, but can your Ai do this?” world…


 RSS Feed
RSS Feed