Image Generators Heat Up
The world was less than amazed when the first text-to-image model was released in 2015. It (alignDRAW) was developed by a team at the University of Toronto, and while it gained recognition in technical circles, the general public was largely unaware it existed. That changed in January of 2021 when OpenAI (pvt) introduced DALL-E1, the first TTI model to catch the eye of the general public. DALL-E was able to understand prompt context and create images that were both creative and unusual, beginning the public’s odyssey into the world of AI image creation. Since then there have been a multitude of such models, some of which are in the public domain, although most are primarily available to subscription users or for a per image fee.
As we have noted previously, the world of text-to-image generators has expanded rapidly and has moved from a niche application to social media star (https://scmr-llc.com/blog/tiny-tostones) status, with new TTI models are being released almost monthly. We count over 20 public models this year to date, with Microsoft (MSFT) the most recent, releasing Mai Image 1, the company’s first fully in-house developed image model and the company’s 3rd overall. Other large companies have jumped on the bandwagon quickly, leaving smaller model developers and labs by the wayside unless they are able to find a niche where they excel over more general TTI models.
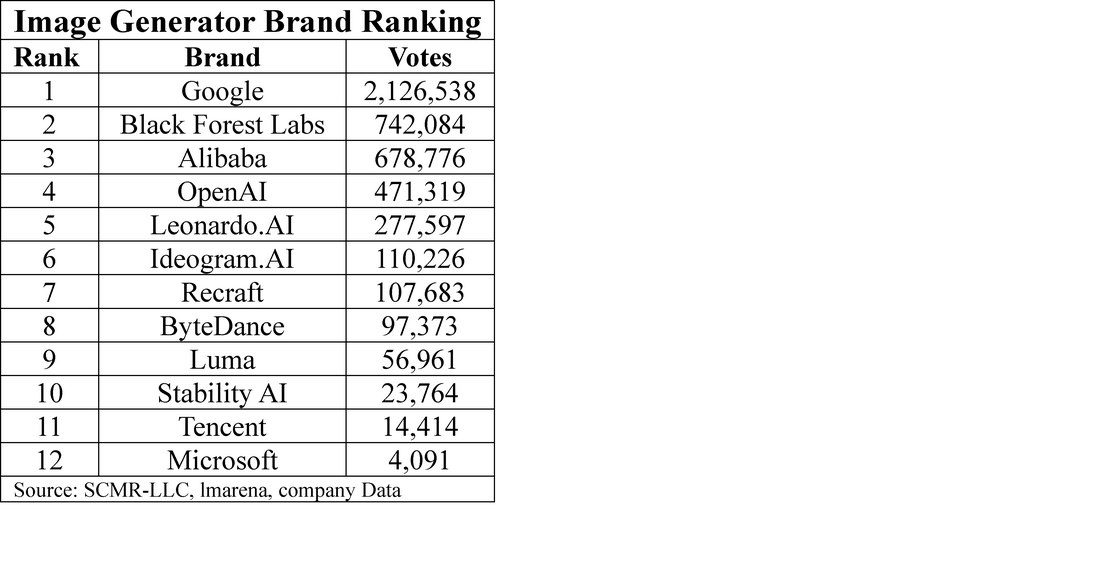
We have put together a list of many of the current public text-to-image models (not all) that are available to consumers, most for a fee (see the “open Source” column for those that are free). There are some that are intentionally missing, such as OpenAI’s Sora and Sora 2, as Sora is only available to ChatGPT Plus & Pro subscribers in the US and Canada, and Sora 2 is an invite only model. We note also that all models listed have a release date in 2025, other than Dalle-E3 as the TTI space is technically in toddler status relative to other CE products. We also show a ‘vote’ column, a capture from an image generator rating site that allows users to vote for the generator that they like best. Given the short lives of some of these models it is a bit difficult to reconcile popularity and time from release, but there are some that are obviously more popular than others, and not all are from major AI companies.
As we have noted previously, the world of text-to-image generators has expanded rapidly and has moved from a niche application to social media star (https://scmr-llc.com/blog/tiny-tostones) status, with new TTI models are being released almost monthly. We count over 20 public models this year to date, with Microsoft (MSFT) the most recent, releasing Mai Image 1, the company’s first fully in-house developed image model and the company’s 3rd overall. Other large companies have jumped on the bandwagon quickly, leaving smaller model developers and labs by the wayside unless they are able to find a niche where they excel over more general TTI models.
We have put together a list of many of the current public text-to-image models (not all) that are available to consumers, most for a fee (see the “open Source” column for those that are free). There are some that are intentionally missing, such as OpenAI’s Sora and Sora 2, as Sora is only available to ChatGPT Plus & Pro subscribers in the US and Canada, and Sora 2 is an invite only model. We note also that all models listed have a release date in 2025, other than Dalle-E3 as the TTI space is technically in toddler status relative to other CE products. We also show a ‘vote’ column, a capture from an image generator rating site that allows users to vote for the generator that they like best. Given the short lives of some of these models it is a bit difficult to reconcile popularity and time from release, but there are some that are obviously more popular than others, and not all are from major AI companies.

Users of these models can vote for their favorite, and while this is a biased and unscientific survey, it is more of an indication of how useful these models are than many of the benchmarks that are commonly used for image generators. While Google is the obvious dominant force, much smaller Black Forest Labs (the team that developed Stable Diffusion) beat out all others, including OpenAI in this very practical user survey.
Again, while we see these rankings of equal value to benchmarks, when it comes to what users expect when using text-to-image models, there are very specific features/areas that are key to a TTI model’s success as shown below:
There is little said about the profitability of text-to-image models and there is a train of thought that says they are a necessary part of a full model stack, even if they generate a loss, but along with generative AI they also require a massive amount of compute power during training. The good news for developers is TTI models typically have fewer parameters than generative models because they are so specialized, and Image models don’t process every pixel of an image by working in ‘latent space’, a compressed representation of the image, reducing the amount of computing power necessary to train the model. Generative AI models need to process every token sequentially to understand its relationships, pushing the amount of processing power and costs to near theoretical limits. Image models are therefore less expensive to train than generative models, however at the inference level, when the model is interacting with users, the compute power necessary to understand the prompt and then create an image is greater than that of generative AI, where the result is just a relatively simple text response. Net, the TTI model is less expensive to train but more expensive to run than a generative AI model.
In the relatively short time we have been using TTI models we have already seen a big improvement in performance, particularly recently with the release of Google’s Nano-banana model, which allows users to make modifications on an image without changing the basic structure of the image, something many models struggle to do. Nothing is more frustrating to a user than working on a complex prompt, getting the correct image, only to find a spelling error or physical glitch. When trying to correct the issue, the AI changes the image and rarely can find its way back to the correct one. Nano-banana has been able to maintain a stable image while making most corrections. This might seem a basic function for an image model, but until recently it was a dream rather than a reality.
As is obvious, the TTI space is evolving very rapidly and will continue to advance, perhaps faster than generative AI, and while those that decry Ai image generation as a job killer or an invasion of personal privacy are missing the concept that almost anyone, even those whose drawing ability is so poor that a straight line is a challenge, can now let their creative juices flow through a text-to-image model. The better you can describe it, the better the image will be…
Here's an example:
Can you create an image of a gray striped tabby cat?
- Adherence – A measure of how accurately the image reflects the details given in the prompts, essentially how well the model ‘listens’ to the prompts.
- Realism – The overall visual believability and appeal that the image has, whether it was specified in the prompt or not.
- Typography – The ability of the model to generate clear, legible, and correctly spelled text within an image.
- Control – The tools given to the user to make adjustments, fine tune, or edit an image
- Ease of Use – How easy it is to operate the model and make changes
- Cost – While model builders talk about open source, they rarely offer same. We note there are only a few models that are not fee based. Stable Diffusion has been open source since its initial release in 2022.
There is little said about the profitability of text-to-image models and there is a train of thought that says they are a necessary part of a full model stack, even if they generate a loss, but along with generative AI they also require a massive amount of compute power during training. The good news for developers is TTI models typically have fewer parameters than generative models because they are so specialized, and Image models don’t process every pixel of an image by working in ‘latent space’, a compressed representation of the image, reducing the amount of computing power necessary to train the model. Generative AI models need to process every token sequentially to understand its relationships, pushing the amount of processing power and costs to near theoretical limits. Image models are therefore less expensive to train than generative models, however at the inference level, when the model is interacting with users, the compute power necessary to understand the prompt and then create an image is greater than that of generative AI, where the result is just a relatively simple text response. Net, the TTI model is less expensive to train but more expensive to run than a generative AI model.
In the relatively short time we have been using TTI models we have already seen a big improvement in performance, particularly recently with the release of Google’s Nano-banana model, which allows users to make modifications on an image without changing the basic structure of the image, something many models struggle to do. Nothing is more frustrating to a user than working on a complex prompt, getting the correct image, only to find a spelling error or physical glitch. When trying to correct the issue, the AI changes the image and rarely can find its way back to the correct one. Nano-banana has been able to maintain a stable image while making most corrections. This might seem a basic function for an image model, but until recently it was a dream rather than a reality.
As is obvious, the TTI space is evolving very rapidly and will continue to advance, perhaps faster than generative AI, and while those that decry Ai image generation as a job killer or an invasion of personal privacy are missing the concept that almost anyone, even those whose drawing ability is so poor that a straight line is a challenge, can now let their creative juices flow through a text-to-image model. The better you can describe it, the better the image will be…
Here's an example:
Can you create an image of a gray striped tabby cat?

Can you create an image of a gray stripped tabby cat with blue eyes and silver ear tufts, sitting on a wooden crate in front of a red barn?

Can you add two gray and white kittens sitting next to the cat, both with blue eyes and silver ear tufts, but make one with a bit of orange in the fur color. Can you make it a bit sunnier and make the barn a more intense red?

Can you keep everything the same and put a bush next to the crate?

Can you keep everything the same but put a washed out "Borden's Evaporated Milk" label on the front of the crate that the cats are sitting on?














 RSS Feed
RSS Feed