Body Snatchers
AI systems are always searching for data and with more models being trained on similar or the same basic datasets, the search for ‘fresh data’ is of great importance to model builders. As we have previously noted, the quality of model training data has considerable consequence in keeping the model from becoming ‘uncreative’ and losing its ability to generalize when it sees new or previously unseen data. As we have also noted, model builders use the internet to harvest data by sending out bots to scrape data from websites that seem to have ‘fresh’ data that would help to keep the training data from becoming stale.
This is not a problem for large sites, but it can become a serious problem for small ones, as the bots are inherently impatient, some making tens of thousands of server requests to try to download information from the site quickly. This can overload the server, which was not designed for such high-volume traffic and can crash the site. Further, the bots use a large number of IP addresses, which keeps them under the radar of those systems that look for high volume requests from a single IP address. In theory such bots are not supposed to crawl sites that have a paywall and are not supposed to collect any data that would allow for the tracking of personal identities. A simple file on the website called Robots.txt tells bots what they can and cannot look at on the site or can limit their access based on their IP. That said, it is imperative for that file to be correctly configured, even if there are warnings about scraping the site in other places, or the bots will scrape everything on the site.
Here's the example (real):
A small company with only seven employees has spent 10 years building a database of 3D image files it has scanned from human models (with their permission). These are 3D files and images of hands, feet, and other body parts, all the way to full body scans. They sell these images, which can include a variety of facial expressions or movements, with over 65,000pages of content, each with at least three images per page. They sell these images to 3D artists, game developers, or anyone who needs images with real human features.
This is not a problem for large sites, but it can become a serious problem for small ones, as the bots are inherently impatient, some making tens of thousands of server requests to try to download information from the site quickly. This can overload the server, which was not designed for such high-volume traffic and can crash the site. Further, the bots use a large number of IP addresses, which keeps them under the radar of those systems that look for high volume requests from a single IP address. In theory such bots are not supposed to crawl sites that have a paywall and are not supposed to collect any data that would allow for the tracking of personal identities. A simple file on the website called Robots.txt tells bots what they can and cannot look at on the site or can limit their access based on their IP. That said, it is imperative for that file to be correctly configured, even if there are warnings about scraping the site in other places, or the bots will scrape everything on the site.
Here's the example (real):
A small company with only seven employees has spent 10 years building a database of 3D image files it has scanned from human models (with their permission). These are 3D files and images of hands, feet, and other body parts, all the way to full body scans. They sell these images, which can include a variety of facial expressions or movements, with over 65,000pages of content, each with at least three images per page. They sell these images to 3D artists, game developers, or anyone who needs images with real human features.
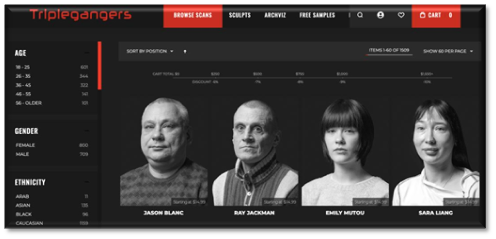
Figure 4 - Sample page - Source: Triplegangers
Unfortunately a recent visit to the site by OpenAI’s (pvt) GPTBots sent tens of thousands of server requests in order to download the entire content of the site. As the site requires payment to download its content, the bot should not have been able to make those requests, but it did and it crashed the site, which also had a Robots.txt file and a clear Code of Conduct and Terms of Use that strictly forbid scraping. With the bot using different IP addresses for each request, it seems to the security software that they are coming from multiple users, and the only way to figure out how to block those and other crawlers is to spend days working through each server request to confirm its legitimacy. In the meanwhile, the site was down, potentially the rights of the human models have been violated, and the site will receive a huge bill from Amazon (AMZN) for the massive server surge that the bot caused. To make it worse they still have not found a way to get OpenAI to delete the material, other than sending an official request.
As it turns out, most small sites don’t know that they have been scraped as some bots are more subtle in making content requests to the server. If they don’t cause a server overload, the only way one would know that there proprietary data was scraped would be by manually searching through pages of server logs, something small sites just don’t have the time to do. So while there are ‘good’ bots that observe rules and keep themselves under control, there are ‘bad’ bots that just hammer away at sites and can cause the damage indicated above. It is almost impossible to guard against the wide variety of crawlers that are developed almost daily and the very aggressive needs for ‘fresh data’, so small sites remain at risk to this AI menace This was a real case of bodysnatching…
As it turns out, most small sites don’t know that they have been scraped as some bots are more subtle in making content requests to the server. If they don’t cause a server overload, the only way one would know that there proprietary data was scraped would be by manually searching through pages of server logs, something small sites just don’t have the time to do. So while there are ‘good’ bots that observe rules and keep themselves under control, there are ‘bad’ bots that just hammer away at sites and can cause the damage indicated above. It is almost impossible to guard against the wide variety of crawlers that are developed almost daily and the very aggressive needs for ‘fresh data’, so small sites remain at risk to this AI menace This was a real case of bodysnatching…

Figure 5 - Bodysnatchers - Source: https://mymacabreroadtrip.com/
 RSS Feed
RSS Feed