The Ghost in the Machine
Hallucinations in humans are situations where the brain believes it is receiving sensory information but is not. It pulls stored information from memory, sometimes distorting it or combining it with other information, but presenting it as if it were real sensory information. Human hallucinations are not fully understood but are thought to be the result of an imbalance in certain neurotransmitters like dopamine, serotonin, glutamate, or GABA, but the ‘how’ is better understood than the ‘why’.
AI systems, particularly LLMs, are also subject to hallucinations, and are also poorly understood, even by those that developed the underlying code. As LLMs typically have no access to live sensory information AI hallucinations are textual or visual (image or video), such as creating non-factual information or adding extra fingers to the image of a hand in an image or video. While the motivation behind human hallucinations can be traced to brain chemicals, the motivation behind hallucinations in LLMs is quite different. LLMs are essentially devices that predict the most likely sequence of words based on the information they have been trained on. This allows for fluency but is based on statistical probability rather than factual accuracy.
But what makes an LLM create false information (hallucinate)? There are no mismatched neurotransmitters in LLMs and no chance of parental neglect or a lack of ‘hugs’, and while AI systems seem complex, they are quite simple when compared to the human brain. Ai neurons receive input that has a number of values (think ‘descriptions’) attached. The AI multiplies each value by a weight value it learned during training, sums all of the products, and passes the modified input to another neuron in the next layer. Think of an Ai neuron as a math genius who cannot read or write. Super at math but nothing else. Human neurons are different. They are diverse with many specialized functions (sensory, motor, intermodal, etc.) and are ‘plastic’, meaning they can change their connections over time. Human neurons can perform many functions at once because they are based on chemical reactions happening in different parts of the neuron, while AI neurons are software constructs that can perform only sequential mathematical functions.
While one might understand that among the 86 billion neurons in the human brain and the potential for up to 100 trillion synapse connections, it is understandable that there could be something blocking a neurotransmitter somewhere causing a hallucination, especially considering the diverse functions and large number of neurotransmitters. AI ‘brains’ are electrical, so there is always the potential for a bad component somewhere in an LLM, but those issues would be relatively easy to debug. So it would seem that there is little that could go wrong with the relatively simple basic math systems in an LLM, even though there are many of them.
Problems seem to stem from those ‘weights’ that we mentioned earlier. When an AI is being trained, it looks at massive amounts of data to discover patterns. The patterns are far more complex than ‘this comes after this 82.6% of the time’ or ‘a picture with a dog will be an Irish setter 11.34% of the time’ as they are linked across many tokens (‘if these two tokens are next to each other and the word is a noun then the next three tokens will be ‘and’ 18,6% of the time’), linking the two tokens to the next three. The weights mentioned above, represent these complex patterns, and with 200 billion possible weights for a model like ChatGPT 4.o, there is an incredible amount of pattern refinement that can be accomplished. That said, learning those weights means the model must rely on the training data. If the training data is very diverse, the weights will reflect that diversity and present the widest variety of patterns for the model to learn, but if the training data is incomplete or narrow, the accuracy of those weights will be less so. Once training is finished, the model’s final weights are locked in.
So logic holds that if you want your model to give the most accurate answers, train it on tons of data. The problem ius that the more ‘topics’ the training data contains, the less complete each topic is, meaning that a description of the process for cracking crude oil into various by-products might not fully describe the details. To compensate, model builders can focus on training data that is more specialized, and typically more complete, but there is a fine line where the model becomes a bit too specialized and is less able to understand and correctly answer generalize broad conceptual queries.
Of course, there is also a lack of real-world rules and laws that the model does not have, so the idea of adding what turns out to be an extra finger in an image because the model knows humans have five on each hand but doesn’t understand that the 5th finger is hidden behind the others in the image, makes sense. However LLMs are probability based and not accuracy based, which means they will create words, sentences, and answers that have the highest probability of being correct, but might not be factually correct. There is a strong correlation between a strong statistical pattern and the correctness of a particular piece of information, but the inherent nature of statistical models does not allow them to be 100% accurate.
The basic purpose of an LLM is to answer a user’s query, but if it does not have the answer, creating a plausible sounding answer might fulfill that goal. The answer could have a high statistical pattern rating and could be based on similar information but is incorrect or does not exist. In such cases, the AI is only trying to fulfill its base objective, answer the question as best as possible, but without the necessary information during training, it fills the gap with something it made up.
There is one other factor that might cause an LLM to hallucinate, but it is a human frailty. LLMs have mechanisms, essentially thresholds, that tell it when to answer a query or when to say “I don’t know”. If an LLM is set to a low confidence threshold it will cause the LLM to say “I don’t know” often or add caveats to the answer (Gemini does this), while setting that threshold too high will cause it to make up answers more often. This leaves some of the blame for LLM hallucinations on its developers who set the confidence levels when designing the system. While the onus is on the LLM in such cases, some blame has to be passed on to others.
Hallucinations in humas are debilitating, distracting, or bothersome. Hallucinations in AI systems have broader effects, and even with the decline in hallucination incidents as models improve, the results of same can have financial consequences. According to Kiva (pvt), $67.4 billion in global losses were linked to AI hallucinations across all industries in 2024[1] and 47% of enterprise AI users admitted they made at least one major business decision based on hallucinated AI output,[2] while 83% of legal professionals encountered fake case law when using LLMs for legal research.[3] The point is, when figuring the cost saving associated with Ai, one has to include both the cost of rechecking all data supplied by the AI and the cost of any potential bad decisions made using unchecked Ai data. While Ai certainly can be a time saver, there are hidden costs that are usually only mentioned as an aside or noted in ‘Terms & Conditions’. Just like human employees, AIs make mistakes. The only difference is with human employees y
[1] McKinsey AI Impact Report, 2025)
[2] Deloitte Global Survey - 2025
[3] Harvard Law School Digital Law Review - 2024
AI systems, particularly LLMs, are also subject to hallucinations, and are also poorly understood, even by those that developed the underlying code. As LLMs typically have no access to live sensory information AI hallucinations are textual or visual (image or video), such as creating non-factual information or adding extra fingers to the image of a hand in an image or video. While the motivation behind human hallucinations can be traced to brain chemicals, the motivation behind hallucinations in LLMs is quite different. LLMs are essentially devices that predict the most likely sequence of words based on the information they have been trained on. This allows for fluency but is based on statistical probability rather than factual accuracy.
But what makes an LLM create false information (hallucinate)? There are no mismatched neurotransmitters in LLMs and no chance of parental neglect or a lack of ‘hugs’, and while AI systems seem complex, they are quite simple when compared to the human brain. Ai neurons receive input that has a number of values (think ‘descriptions’) attached. The AI multiplies each value by a weight value it learned during training, sums all of the products, and passes the modified input to another neuron in the next layer. Think of an Ai neuron as a math genius who cannot read or write. Super at math but nothing else. Human neurons are different. They are diverse with many specialized functions (sensory, motor, intermodal, etc.) and are ‘plastic’, meaning they can change their connections over time. Human neurons can perform many functions at once because they are based on chemical reactions happening in different parts of the neuron, while AI neurons are software constructs that can perform only sequential mathematical functions.
While one might understand that among the 86 billion neurons in the human brain and the potential for up to 100 trillion synapse connections, it is understandable that there could be something blocking a neurotransmitter somewhere causing a hallucination, especially considering the diverse functions and large number of neurotransmitters. AI ‘brains’ are electrical, so there is always the potential for a bad component somewhere in an LLM, but those issues would be relatively easy to debug. So it would seem that there is little that could go wrong with the relatively simple basic math systems in an LLM, even though there are many of them.
Problems seem to stem from those ‘weights’ that we mentioned earlier. When an AI is being trained, it looks at massive amounts of data to discover patterns. The patterns are far more complex than ‘this comes after this 82.6% of the time’ or ‘a picture with a dog will be an Irish setter 11.34% of the time’ as they are linked across many tokens (‘if these two tokens are next to each other and the word is a noun then the next three tokens will be ‘and’ 18,6% of the time’), linking the two tokens to the next three. The weights mentioned above, represent these complex patterns, and with 200 billion possible weights for a model like ChatGPT 4.o, there is an incredible amount of pattern refinement that can be accomplished. That said, learning those weights means the model must rely on the training data. If the training data is very diverse, the weights will reflect that diversity and present the widest variety of patterns for the model to learn, but if the training data is incomplete or narrow, the accuracy of those weights will be less so. Once training is finished, the model’s final weights are locked in.
So logic holds that if you want your model to give the most accurate answers, train it on tons of data. The problem ius that the more ‘topics’ the training data contains, the less complete each topic is, meaning that a description of the process for cracking crude oil into various by-products might not fully describe the details. To compensate, model builders can focus on training data that is more specialized, and typically more complete, but there is a fine line where the model becomes a bit too specialized and is less able to understand and correctly answer generalize broad conceptual queries.
Of course, there is also a lack of real-world rules and laws that the model does not have, so the idea of adding what turns out to be an extra finger in an image because the model knows humans have five on each hand but doesn’t understand that the 5th finger is hidden behind the others in the image, makes sense. However LLMs are probability based and not accuracy based, which means they will create words, sentences, and answers that have the highest probability of being correct, but might not be factually correct. There is a strong correlation between a strong statistical pattern and the correctness of a particular piece of information, but the inherent nature of statistical models does not allow them to be 100% accurate.
The basic purpose of an LLM is to answer a user’s query, but if it does not have the answer, creating a plausible sounding answer might fulfill that goal. The answer could have a high statistical pattern rating and could be based on similar information but is incorrect or does not exist. In such cases, the AI is only trying to fulfill its base objective, answer the question as best as possible, but without the necessary information during training, it fills the gap with something it made up.
There is one other factor that might cause an LLM to hallucinate, but it is a human frailty. LLMs have mechanisms, essentially thresholds, that tell it when to answer a query or when to say “I don’t know”. If an LLM is set to a low confidence threshold it will cause the LLM to say “I don’t know” often or add caveats to the answer (Gemini does this), while setting that threshold too high will cause it to make up answers more often. This leaves some of the blame for LLM hallucinations on its developers who set the confidence levels when designing the system. While the onus is on the LLM in such cases, some blame has to be passed on to others.
Hallucinations in humas are debilitating, distracting, or bothersome. Hallucinations in AI systems have broader effects, and even with the decline in hallucination incidents as models improve, the results of same can have financial consequences. According to Kiva (pvt), $67.4 billion in global losses were linked to AI hallucinations across all industries in 2024[1] and 47% of enterprise AI users admitted they made at least one major business decision based on hallucinated AI output,[2] while 83% of legal professionals encountered fake case law when using LLMs for legal research.[3] The point is, when figuring the cost saving associated with Ai, one has to include both the cost of rechecking all data supplied by the AI and the cost of any potential bad decisions made using unchecked Ai data. While Ai certainly can be a time saver, there are hidden costs that are usually only mentioned as an aside or noted in ‘Terms & Conditions’. Just like human employees, AIs make mistakes. The only difference is with human employees y
[1] McKinsey AI Impact Report, 2025)
[2] Deloitte Global Survey - 2025
[3] Harvard Law School Digital Law Review - 2024
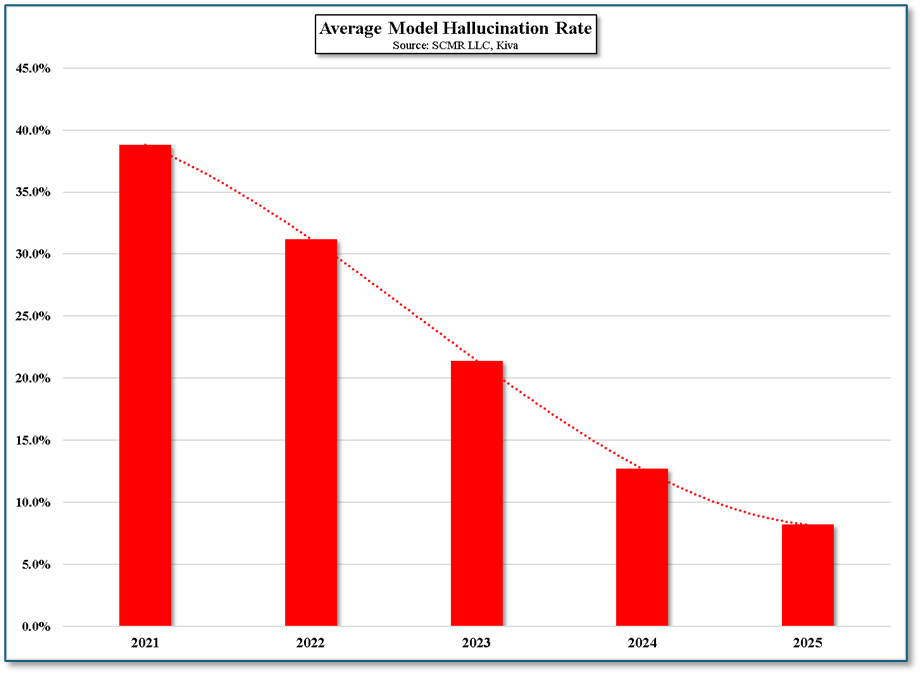
Figure 1- Average Model Hallucination Rate - Source: SCMR LLC, Kiva
Examples of AI hallucinations:
[1] https://www.bbc.com/news/articles/cd11gzejgz4o
[2] https://arstechnica.com/ai/2025/04/cursor-ai-support-bot-invents-fake-policy-and-triggers-user-uproar/
[3] https://inmoment.com/blog/ai-hallucination/
[4] https://www.nngroup.com/articles/ai-hallucinations/
[5] https://www.nngroup.com/articles/ai-hallucinations/
[6] https://www.infosecurity-magazine.com/opinions/ai-dark-side-hallucinations/
[7] https://cacm.acm.org/news/shining-a-light-on-ai-hallucinations/
[8] https://www.allaboutai.com/resources/ai-statistics/ai-hallucinations/
- Google’s (GOOG) AI Overview system was telling people that geologists suggest eating rocks. In reality the AI was referencing a satirical article from the Onion that was republished on a geological site because they thought it was funny.[1]
- Last month Cursor’s (pvt) AI support agent made up a non-existent policy and told users that they could only use the software on one device, causing some to cancel subscriptions.[2]
- Google’s Gemini falsely stated in a promotional video that the James Webb Space Telescope took the first image of a planet outside of our solar system. The actual first image was taken by the European Southern Observatory’ s Very Large Telescope in 2004.[3]
- In a Columbia Journalism Review study, ChatGPT was asked to attribute quotes from popular journalism sites. The AI falsely attributed 76% of 200 quotes, rarely indicating uncertainty about its answers.[4]
- Specialized legal AI tools from LexisNexis (RELX) and Thomson Reuters (TRI) produced incorrect information in at least 1 out of 6 benchmark queries, demonstrating that hallucinations are not limited to general-purpose models[5]
- In 2025, OpenAI (pvt) faced a privacy complaint in Europe after its chatbot falsely accused an individual of serious crimes, demonstrating how AI hallucinations can escalate to real-world legal and reputational harm[6]
- One notorious hallucination example involved an AI suggesting the addition of glue to a pizza recipe to help toppings stick, a clear fabrication with potentially dangerous consequences[7]
- Hallucinations are especially common in fields like law, medicine, and programming. For instance, even the most advanced AI models hallucinate legal information 6.4% of the time and programming content 5.2% of the time[8]
[1] https://www.bbc.com/news/articles/cd11gzejgz4o
[2] https://arstechnica.com/ai/2025/04/cursor-ai-support-bot-invents-fake-policy-and-triggers-user-uproar/
[3] https://inmoment.com/blog/ai-hallucination/
[4] https://www.nngroup.com/articles/ai-hallucinations/
[5] https://www.nngroup.com/articles/ai-hallucinations/
[6] https://www.infosecurity-magazine.com/opinions/ai-dark-side-hallucinations/
[7] https://cacm.acm.org/news/shining-a-light-on-ai-hallucinations/
[8] https://www.allaboutai.com/resources/ai-statistics/ai-hallucinations/

 RSS Feed
RSS Feed