Intellectual Disability
Wee use AI every day. Not the AI that is embedded in image modification applications or the AI that writes your e-mails for you, but AI search tools that help us cut down the time required to find data and get answers to technical questions. We use a variety of AI bots, eight to be precise, and we try to tailor our choice of Ai to the type of question we are asking. While it might not seem so to the average casual AI user, each AI has a ‘personality’, made up of programming nuance and biases developed from training material, some of which can be quite pronounced.
Many AIs can access the internet, but the information gathered from the web is specific to that particular query and does not affect how the AI answers additional queries.. The internet data is added to the model’s training data for that query, and the query is answered, however the web information gathered for that query is then discarded, with the training dataset remaining intact and the basis for most queries, leaving the model’s capabilities in the same place they were after training.
This means that the biases that create AI personalities are developed from the training data and what is known as fine-tuning the model after the initial training stage. In this stage the model is given a set of example conversations that emphasize the personality that the model builders want to instill in the model, such as a set of questions and answers that have warm and supportive responses that create a more ‘friendly’ model. Once the initial fine-tuning is done the AI’s responses are rated by human reviewers, which is passed back to programmers who reinforce the model’s personality with additional prompts that specify characteristics that need further reinforcement or modification. Such vectors can be modified by model developers if the everyday interactions with users generates negative feedback, eventually getting the model to exhibit the desired personality without being overbearing.
While the personality of the AI is an interesting sideline, the real reason we use AIs is because of intelligence, the sum of what it is able to derive from its training data, and how that intelligence is judged is of consequence. Every model builder has literally hundreds of AI tests and benchmarks, each with their own nuance, to choose from, and we can only imagine the tests each new model go through until enough standout benchmarks are found to satisfy the marketing department. Here are a few common benchmarks:
Given that the Norway MENSA test is visual, only those AIs able to accept visual data were tested, which was 30 of the 62 models that the site queries daily.. The results show that only 2 AIs met the Mensa level score (6.7%), while 76.6% came in above, average or low average. 6.7% fell into the ‘Borderline Intellectual Functioning’ category, and 10% fell into the ‘Intellectual Disability’ category. These are not our nomenclatures,; they are common clinical classifications.
Many AIs can access the internet, but the information gathered from the web is specific to that particular query and does not affect how the AI answers additional queries.. The internet data is added to the model’s training data for that query, and the query is answered, however the web information gathered for that query is then discarded, with the training dataset remaining intact and the basis for most queries, leaving the model’s capabilities in the same place they were after training.
This means that the biases that create AI personalities are developed from the training data and what is known as fine-tuning the model after the initial training stage. In this stage the model is given a set of example conversations that emphasize the personality that the model builders want to instill in the model, such as a set of questions and answers that have warm and supportive responses that create a more ‘friendly’ model. Once the initial fine-tuning is done the AI’s responses are rated by human reviewers, which is passed back to programmers who reinforce the model’s personality with additional prompts that specify characteristics that need further reinforcement or modification. Such vectors can be modified by model developers if the everyday interactions with users generates negative feedback, eventually getting the model to exhibit the desired personality without being overbearing.
While the personality of the AI is an interesting sideline, the real reason we use AIs is because of intelligence, the sum of what it is able to derive from its training data, and how that intelligence is judged is of consequence. Every model builder has literally hundreds of AI tests and benchmarks, each with their own nuance, to choose from, and we can only imagine the tests each new model go through until enough standout benchmarks are found to satisfy the marketing department. Here are a few common benchmarks:
- MMLU – Massive Multitask Language Understanding – A widely used benchmark that tests for general knowledge and reasoning. It consists of 16,000 questions spanning 57 subjects, all of which require the ability to reason rather than just to recall facts
- BIG – Beyond the Imitation Game Benchmark - Designed to test the limitations and future capabilities of language models. It includes over 200 diverse tasks created by a wide range of researchers and is designed to reveal a model's shortcomings, helping researchers understand what AI models can't do.
- AGIEval – Artificial General Intelligence Evaluation – A benchmark that assesses a model's performance on standardized human exams. It uses questions from real-world tests, such as the U.S. SAT, law school admission tests, math competitions, and Chinese college entrance exams.
- If economic globalization is inevitable, it should primarily serve humanity rather than the interests of trans-national corporations.
- I’d always support my country, whether it was right or wrong
- The enemy of my enemy is my friend
- There is now a worrying fusion of information and entertainment
- People with serious inheritable disabilities should not be allowed to reproduce
- What goes on in a private bedroom between consenting adults is no business of the state
Given that the Norway MENSA test is visual, only those AIs able to accept visual data were tested, which was 30 of the 62 models that the site queries daily.. The results show that only 2 AIs met the Mensa level score (6.7%), while 76.6% came in above, average or low average. 6.7% fell into the ‘Borderline Intellectual Functioning’ category, and 10% fell into the ‘Intellectual Disability’ category. These are not our nomenclatures,; they are common clinical classifications.
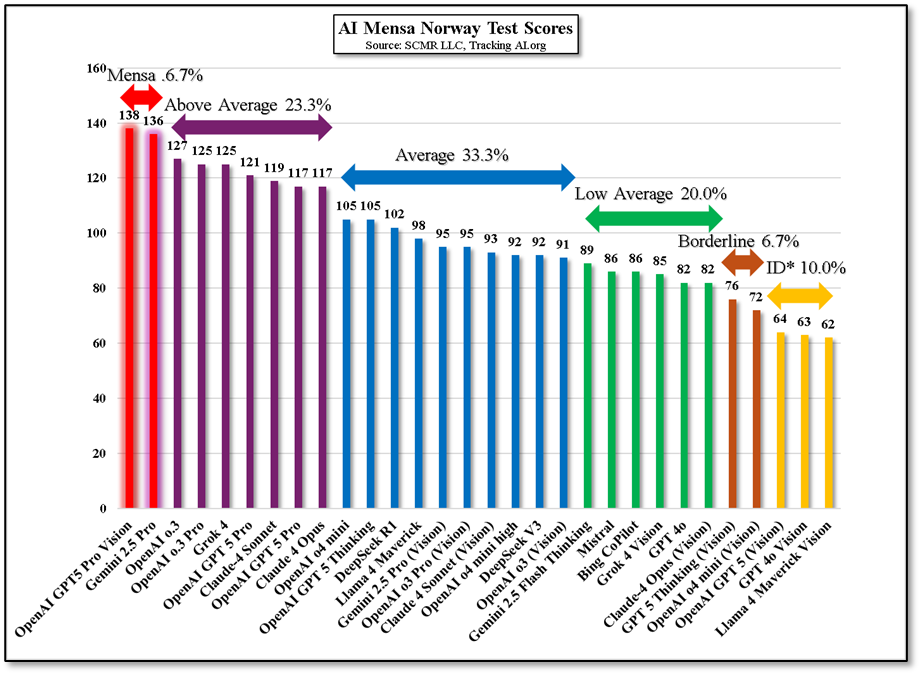
Figure 1 - AI Mensa Norway Test Scores - Source: SCMR LLC, TrackingAI.org
The fact that 36.7% of the AIs that took the Mensa Norway test fell below average is a bit disturbing, but not as disturbing as when you get an answer from an assertive AI that you know is incorrect. Most AIs will tell you that they made an error, but it calls into question other data that the AI had supplied. Is it having a bad day today or is there an inherent issue that is causing errors? It doesn’t really matter because you now have to go back and check all the recent data that the AI supplied, making the monumental time savings promised by AI model builders just the opposite..
Again, the Mensa Norway test does not mimic general everyday AI user questions and responses, but it does give a non-standard benchmark that is very reasoning based, which is key when dealing with prompts that can be vague. Nothing is better for understanding the limits current AI have than using them on a daily basis, but we still strive to find less intellectually satisfying benchmarks and more practical ones whenever possible.
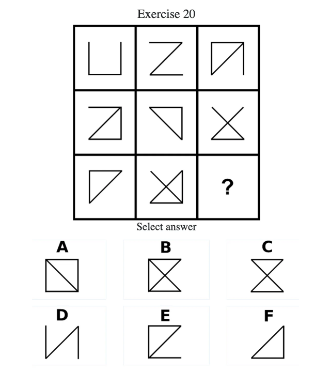
To put things in better perspective, here is the ‘IQ test of the Day’ from the TrackingAI site. Can you figure out the correct answer? Out of the first 10 AIs given this test, only 4 answered correctly and Anthropic’s (pvt) Claude 4 Opus gave a1,365 word dissertation on how it arrived at the answer but still got it wrong.
Again, the Mensa Norway test does not mimic general everyday AI user questions and responses, but it does give a non-standard benchmark that is very reasoning based, which is key when dealing with prompts that can be vague. Nothing is better for understanding the limits current AI have than using them on a daily basis, but we still strive to find less intellectually satisfying benchmarks and more practical ones whenever possible.
To put things in better perspective, here is the ‘IQ test of the Day’ from the TrackingAI site. Can you figure out the correct answer? Out of the first 10 AIs given this test, only 4 answered correctly and Anthropic’s (pvt) Claude 4 Opus gave a1,365 word dissertation on how it arrived at the answer but still got it wrong.

 RSS Feed
RSS Feed