Chatting up the Internet
AI chatbots are not new, despite the recent flood of conversational LLMs. ELIZA, developed by Joseph Weizenbaum at MIT AI lab in 1964 is considered the ‘first’ AI chatbot as it used pattern matching as the basis for its responses, but over the years much of what were known as chatbots were based on pre-written scripts and rule based systems such as the “Ask XYZ” systems that have been available on many websites for years. The current crop of AI LLM based chatbots are far more sophisticated and based on large, high-performance models. More recently chatbots features have been extended to included internet search capabilities and early predictions were that search enabled chatbots would spell the end to standard search systems.
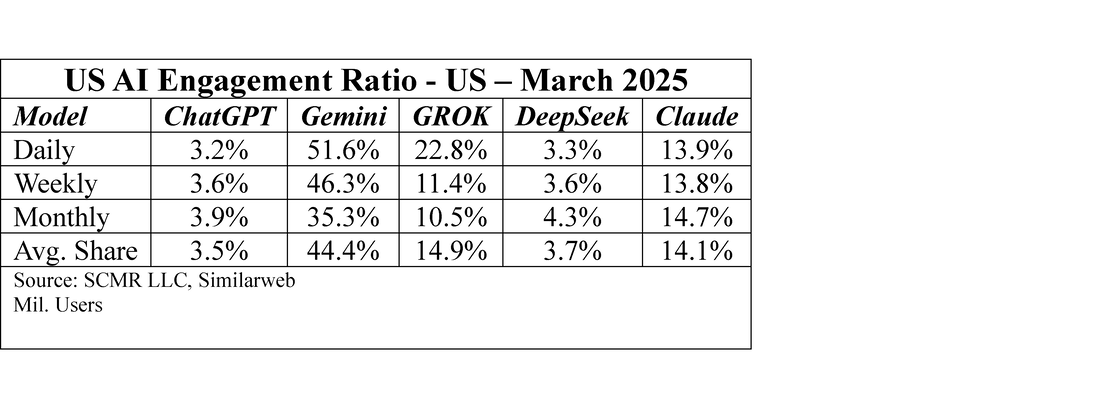
While there certainly has been impact from Chatbot search, the numbers reflect only a small incursion on regular internet search visits. A recent survey[1] indicated that over the period between April 2023 and March 2025, there were 1.863 trillion search engine queries, down 0.51% y/y. The obvious dominant search engine was Google (GOOG) Search with an 87.6% share, and a1.41% reduction in search volume. Bing (MSFT) was a big gainer in search volume, up 27.77% during the period, but even as the number two search engine, Bing only has a 3.2% share of the search market.
[1] Onelittleweb.com
While there certainly has been impact from Chatbot search, the numbers reflect only a small incursion on regular internet search visits. A recent survey[1] indicated that over the period between April 2023 and March 2025, there were 1.863 trillion search engine queries, down 0.51% y/y. The obvious dominant search engine was Google (GOOG) Search with an 87.6% share, and a1.41% reduction in search volume. Bing (MSFT) was a big gainer in search volume, up 27.77% during the period, but even as the number two search engine, Bing only has a 3.2% share of the search market.
[1] Onelittleweb.com

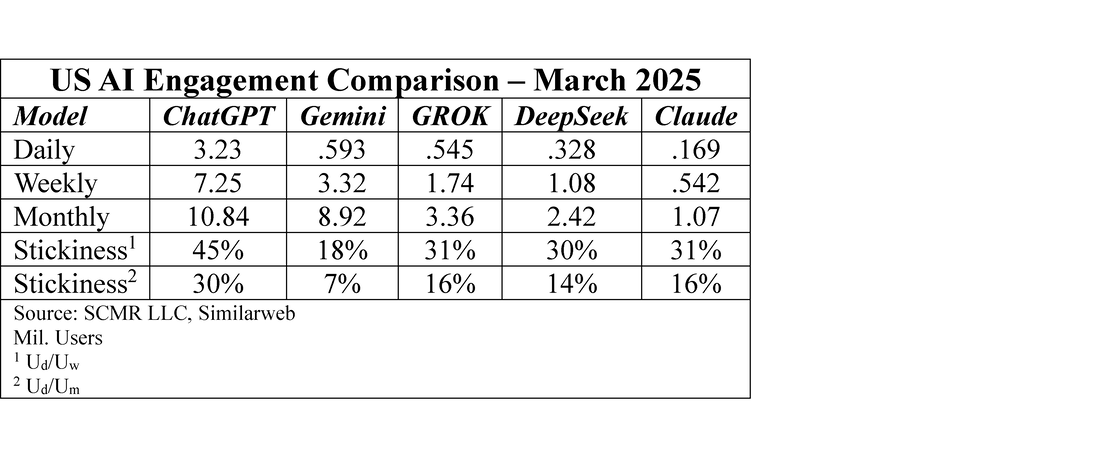
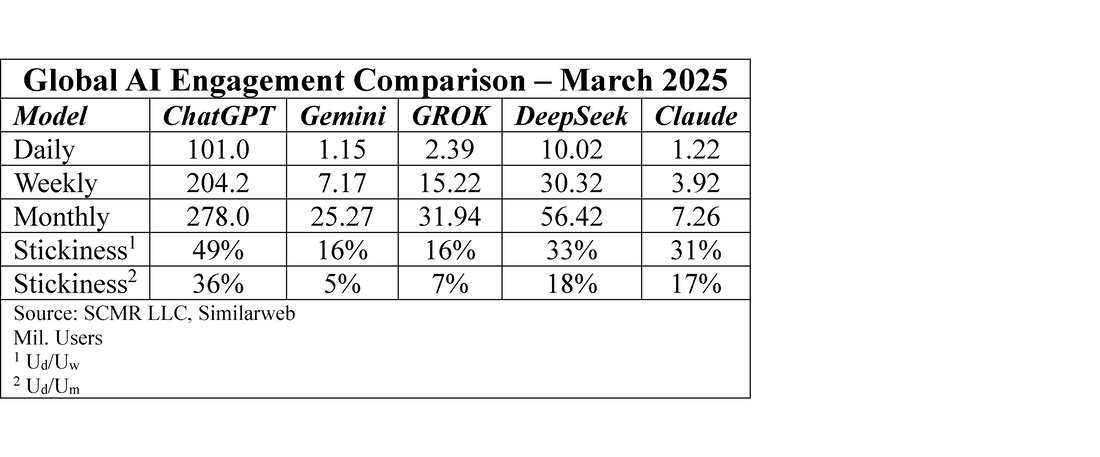
The chatbot search top 10 is similar in that ChatGPT (OpenAI) is the dominant player, however when one looks at the number of searches generated by chatbots against generic search engines, the search engine traffic is over 33 times greater, so as of today, chatbot generated searches are only 2.96% of what is generated by generic search engines. However chatbots offering search capabilities are new, as can be seen by the ‘Search Added’ and the ‘Current Period Change’ columns, where newer chatbot show extremely large y/y increases but small shares. That said, most chatbots that have been around for more than a year have more reasonable search growth rates.
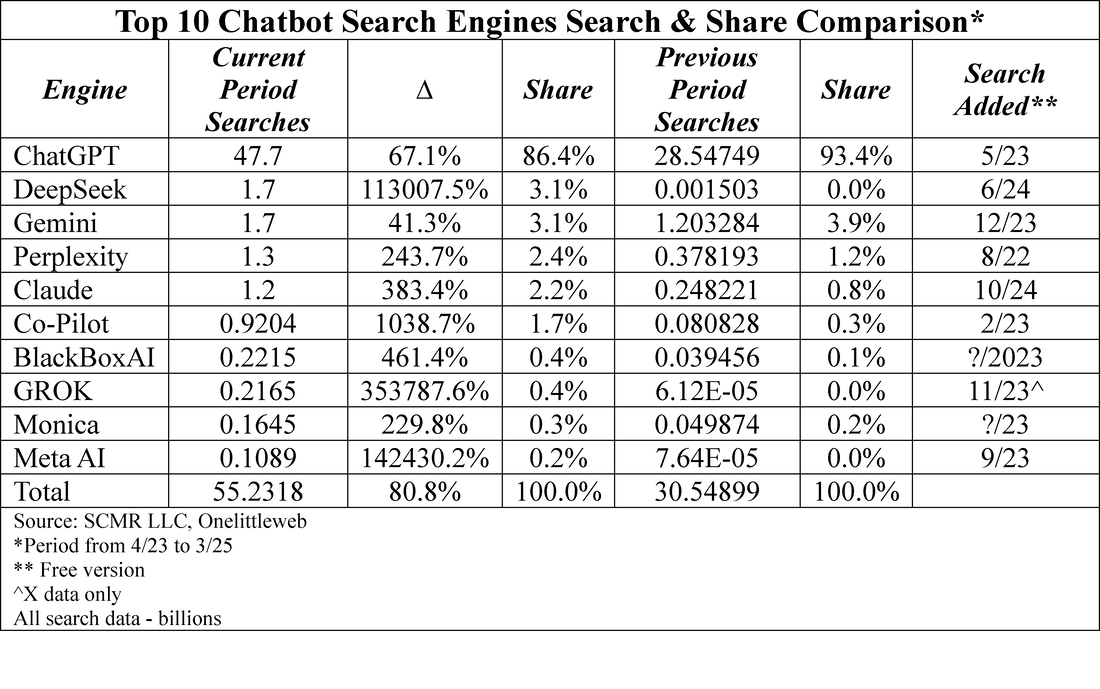
Based on the current data it would seem that chatbot searches have had little effect on overall generic searches, but it is far to early in the cycle to make a long-term judgement. In fact we expect at least Gemini, Google’s LLM/chatbot, chatbot related searches will be incremental to generic search traffic. Likely, although to a lesser degree, Co-Pilot will have the same effect on Bing. On a longer-term basis, as AI chatbots become more embedded in operating systems, it would seem logical that unless you were looking for an answer to a question that you specifically request includes an internet search, the AI would try to answer the question using its most recent training or update data. If, and that is a big if, the data corpus of the AI is broad enough, the answer might not require the chatbot to conduct an internet search, and in that way could weigh on internet search growth.
Much in that scenario depends on how ‘transparent’ the Chatbot is. If it is always available on a home page and looks and acts like a search bar, users will gravitate toward the chatbot/AI. If it has to be chosen, is slow to answer, or comes up with skimpy answers, users will remain generic search fans. But there are other factors that come into play.
It is understandable from the standpoint of the AI owner that they keep the compute time as low as possible, so the default would likely be a query first run without an internet search. However as time goes by, we expect most chatbots will default to include internet search results in query answers, but it is not quite that easy because those searches are not always free.
Currently, some (Perplexity (pvt), Co-Pilot, You.com (pvt), Komo (pvt), Andi (pvt), and Brave Search (pvt)) check the internet on every search, while others either have their own decision mechanism (Gemini, Claude (Anthropic), ChatGPT, GROK (xAI), META (FB)) or users can request an internet search. But going forward things get more complicated. Some CE companies use their own AI infrastructure to run embedded chatbots, while others are based on ChatGPT or other existing infrastructure. Apple (AAPL) runs Apple intelligence on its own servers, it does not ‘pay’ for searches, although the all-in cost of each search is amortized over the infrastructure cost. Others, who might use ChatGPT or Gemini as their AI infrastructure providers that support their chatbot, would have to pay for each search, as both ChatGPT and Google charge on a per search basis, so the advantage goes to those who can support their own chatbot/search infrastructure.
All of this comes down to the value that consumers see in ‘free’ chatbots. If results from trained data are enough for most, chatbots will have a modest impact on search and a modest cost to chatbot owners. If chatbot results are not sufficient for the average user, the cost to maintain ‘free’ chatbots will rise as search fees climb, unless the chatbot owner can convert users to paid plans.
Search has been around for a while and chatbots are relatively new so we expect the impact from chatbots will be small over the next year, but as the general public gets more used to using chatbots, the competition between them will increase and we expect search will be an integral part of all chatbots, especially as the average consumer becomes more aware of chatbot data sources.
We use eight different chatbots, typically querying at least two each time, especially if the query has a need for very current data. We know which chatbots are search oriented and which are not, and which will cite sources, either trained or search related, but the average person will likely use what is easiest, and that is usually whatever is built in to the OS or specific applications, so it is up to the brand to decide what level of search is sufficient for their users. As Ai is such a high-level feature now, the competition will continue to increase and that means more ‘free’ features which is certainly good for consumers
Much in that scenario depends on how ‘transparent’ the Chatbot is. If it is always available on a home page and looks and acts like a search bar, users will gravitate toward the chatbot/AI. If it has to be chosen, is slow to answer, or comes up with skimpy answers, users will remain generic search fans. But there are other factors that come into play.
It is understandable from the standpoint of the AI owner that they keep the compute time as low as possible, so the default would likely be a query first run without an internet search. However as time goes by, we expect most chatbots will default to include internet search results in query answers, but it is not quite that easy because those searches are not always free.
Currently, some (Perplexity (pvt), Co-Pilot, You.com (pvt), Komo (pvt), Andi (pvt), and Brave Search (pvt)) check the internet on every search, while others either have their own decision mechanism (Gemini, Claude (Anthropic), ChatGPT, GROK (xAI), META (FB)) or users can request an internet search. But going forward things get more complicated. Some CE companies use their own AI infrastructure to run embedded chatbots, while others are based on ChatGPT or other existing infrastructure. Apple (AAPL) runs Apple intelligence on its own servers, it does not ‘pay’ for searches, although the all-in cost of each search is amortized over the infrastructure cost. Others, who might use ChatGPT or Gemini as their AI infrastructure providers that support their chatbot, would have to pay for each search, as both ChatGPT and Google charge on a per search basis, so the advantage goes to those who can support their own chatbot/search infrastructure.
All of this comes down to the value that consumers see in ‘free’ chatbots. If results from trained data are enough for most, chatbots will have a modest impact on search and a modest cost to chatbot owners. If chatbot results are not sufficient for the average user, the cost to maintain ‘free’ chatbots will rise as search fees climb, unless the chatbot owner can convert users to paid plans.
Search has been around for a while and chatbots are relatively new so we expect the impact from chatbots will be small over the next year, but as the general public gets more used to using chatbots, the competition between them will increase and we expect search will be an integral part of all chatbots, especially as the average consumer becomes more aware of chatbot data sources.
We use eight different chatbots, typically querying at least two each time, especially if the query has a need for very current data. We know which chatbots are search oriented and which are not, and which will cite sources, either trained or search related, but the average person will likely use what is easiest, and that is usually whatever is built in to the OS or specific applications, so it is up to the brand to decide what level of search is sufficient for their users. As Ai is such a high-level feature now, the competition will continue to increase and that means more ‘free’ features which is certainly good for consumers













 RSS Feed
RSS Feed